An overview of the BDV Reference Model is shown in Fig. 1. It distinguishes between two different elements. On the one hand, it describes the elements that are at the core of the BDVA (also see Chap. “The European Big Data Value Ecosystem”); on the other, it outlines the features that are developed in strong collaboration with related European activities.
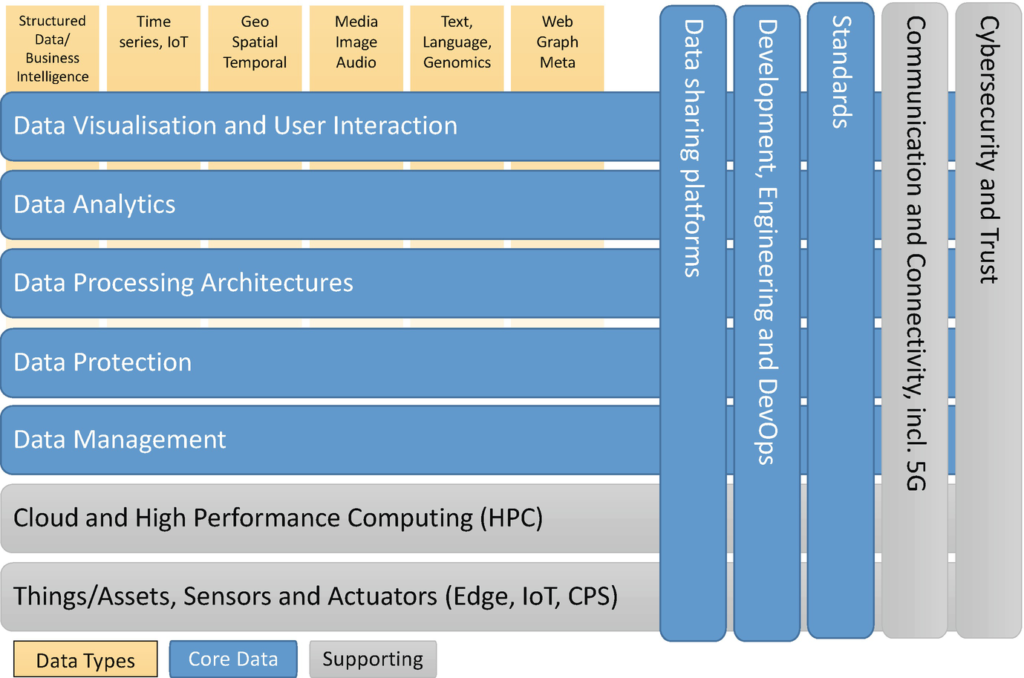
The BDV Reference Model has been developed by the Big Data Value Association (BDVA), taking into account input from technical experts and stakeholders along the whole big data value chain, as well as interactions with other related public-private partnerships (PPPs) ( Zillner et al. 2017). The BDV Reference Model may serve as a common reference framework to locate big data technologies on the overall IT stack. It addresses the main concerns and aspects to be considered for big data value systems.The BDV Reference Model is structured into horizontal and vertical concerns.
- Horizontal concerns cover specific aspects along the data processing chain, starting with data collection and ingestion, and extending to data visualisation. It should be noted that the horizontal concerns do not imply a layered architecture. As an example, data visualisation may be applied directly to collected data (the data management aspect) without the need for data processing and analytics.
- Vertical concerns address cross-cutting issues, which may affect all the horizontal concerns. In addition, vertical concerns may also involve non-technical aspects.
It should be noted that the BDV Reference Model has no ambition to serve as a technical reference architecture. However, it is compatible with such reference architectures, most notably the emerging ISO JTC1 WG9 Big Data Reference Architecture.
The following elements as expressed in the BDV Reference Model are elaborated in the remainder of this section.
Horizontal Concerns
Horizontal concerns cover specific aspects of a big data system. On the one hand, they cover the different elements of the data processing chain, starting from data collection and ingestion up to data visualisation and user interaction. On the other hand, they cover elements that facilitate deploying and operating big data systems, including Cloud and HPC, as well as Edge and IoT.
Data Visualisation and User Interaction
This concern covers advanced visualisation approaches for improved user experience. Data visualisation plays a key role in effectively exploring and understanding big data. Visual analytics is the science of analytical reasoning assisted by interactive user interfaces. Data generated from data analytics processes need to be presented to end-users via (traditional or innovative) multi-device reports and dashboards which contain varying forms of media for the end-user, ranging from text and charts to dynamic, 3D and possibly augmented-reality visualisations. In order for users to quickly and correctly interpret data in multi-device reports and dashboards, carefully designed presentations and digital visualisations are required. Interaction techniques fuse user input and output to provide a better way for a user to perform a task. Common tasks that allow users to gain a better understanding of big data include scalable zooms, dynamic filtering and annotation.
When representing complex information on multi-device screens, the design issues multiply rapidly. Complex information interfaces need to be responsive to human needs and capacity (Raskin 2000). Knowledge workers need to be supplied with relevant information according to the just-in-time approach. Too much information, which cannot be efficiently searched and explored, can obscure the information that is most relevant. In fast-moving time-constrained environments, knowledge workers need to be able to quickly understand the relevance and relatedness of information.
Data Analytics
This concern covers data analytics, which ranges from descriptive analytics (“What happened and why?”) through predictive analytics (“What will happen and when?”) to prescriptive analytics (“What is the best course of action to take?”). The progress of data analytics is key not only for turning big data into value but also for making it accessible to the wider public. Data analytics will have a positive influence on all parts of the data value chain (Cavanillas et al. 2016) and increase business opportunities through business intelligence and analytics while bringing benefits to both society and citizens.
Data analytics is an open, emerging field, in which Europe has strong competitive advantages and a promising business development potential. It has been estimated that governments in Europe could save $149 billion (Manyika et al. 2011) by using big data analytics to improve operational efficiency. Big data analytics can provide additional value in every sector where it is applied, leading to more efficient and accurate processes. A study by the McKinsey Global Institute placed a strong emphasis on analytics, ranking it as the main future driver for US economic growth, ahead of shale oil and gas productions (Lund et al. 2013).
The next generation of analytics will be required to deal with a vast amount of information from different types of sources, with differentiated characteristics, levels of trust and frequency of updating. Data analytics will have to provide insights into the data in a cost-effective and economically sustainable way. On the one hand, there is a need to create complex and fine-grained predictive models for heterogeneous and massive datasets such as time series or graph data. On the other hand, such models must be applied in real time to large amounts of streaming data. This ranges from structured to unstructured data, from numerical data to micro-blogs and streams of data. The latter is exceptionally challenging because data streams, in addition to their volume, are very heterogeneous and highly dynamic, which also calls for scalability and high throughput. For instance, data collection related to a disaster area can easily occupy terabytes in binary GIS formats, and real-time data streams can show bursts of gigabytes per minute.
In addition, an increasing number of big data applications are based on complex models of real-world objects and systems, which are used in computation-intensive simulations to generate new huge datasets. These can be used for iterative refinements of the models, but also for providing new data analytics services which can process extremely large datasets.
Data Processing Architectures
This concern covers optimised and scalable architectures for analytics of both data-at-rest and data-in-motion, thereby delivering low-latency real-time analytics.
The Internet of Things (IoT) is one of the key drivers of the big data phenomenon. Initially, this phenomenon started by applying the existing architectures and technologies of big data that we categorise as data-at-rest, which is data kept in persistent storage. In the meantime, the need for processing immense amounts of sensor data streams has increased. This type of data-in-motion (i.e. non-persistent data processed on the fly) has extreme requirements for low-latency and real-time processing. What has hardly been addressed is the concept of complete processing for the combination of data-in-motion and data-at-rest.
For the IoT domain, these capabilities are essential. They are also required for other domains like social networks or manufacturing, where huge amounts of streaming data are produced in addition to the available big datasets of actual and historical data.
These capabilities will affect all layers of future big data infrastructures, ranging from the specifications of low-level data flows with the continuous processing of micro-messages, to sophisticated analytics algorithms. The parallel need for real-time and large data volume capabilities is a key challenge for big data processing architectures. Architectures to handle streams of data such as the lambda and kappa architectures will be considered as a baseline for achieving a tighter integration of data-in-motion with data-at-rest.
Developing the integrated processing of data-at-rest and data-in-motion in an ad hoc fashion is of course possible, but only the design of generic, decentralised and scalable architectural solutions will leverage their true potential. Optimised frameworks and toolboxes allowing the best use of both data-in-motion (e.g. data streams from sensors) and data-at-rest will leverage the dissemination of reference solutions which are ready and easy to deploy in any economic sector. For example, proper integration of data-in-motion with predictive models based on data-at-rest will enable efficient, proactive processing (detection ahead of time). Architectures that can handle heterogeneous and unstructured data are also important. When such solutions become available to service providers, in a straightforward manner, they will then be free to focus on the development of business models.
The capabilities of existing systems to process such data-in-motion and answer queries in real time and for thousands of concurrent users are limited. Special-purpose approaches based on solutions like Complex Event Processing (CEP) are not sufficient for the challenges posed by the IoT in big data scenarios. The problem of achieving effective and efficient processing of data streams (data-in-motion) in a big data context is far from being solved, especially when considering the integration with data-at-rest and breakthroughs in NoSQL databases and parallel processing (e.g. Hadoop, Apache Spark, Apache Flink, Apache Kafka). Applications, for instance of Artificial Intelligence, are also required to fully exploit all the capabilities of modern and heterogeneous hardware, including parallelism and distribution to boost performance.
To achieve the agility demanded by real-time business and next-generation applications, a new set of interconnected data management capabilities is required.
Data Protection
This concern covers privacy and anonymisation mechanisms to facilitate data protection. This is shown related to data management and processing as there is a strong link here, but it can also be associated with the area of cybersecurity.
Data protection and anonymisation is a major issue in the areas of big data and data analytics. With more than 90% of today’s data having been produced in the last 2 years, a huge amount of person-specific and sensitive information from disparate data sources, such as social networking sites, mobile phone applications and electronic medical record systems, is increasingly being collected. Analysing this wealth and volume of data offers remarkable opportunities for data owners, but, at the same time, requires the use of state-of-the-art data privacy solutions, as well as the application of legal privacy regulations, to guarantee the confidentiality of individuals who are represented in the data. Data protection, while essential in the development of any modern information system, becomes crucial in the context of large-scale sensitive data processing.
Recent studies on mechanisms for protecting privacy have demonstrated that simple approaches, such as the removal or masking of the direct identifiers in a dataset (e.g. names, social security numbers), are insufficient to guarantee privacy. Indeed, such simple protection strategies can be easily circumvented by attackers who possess little background knowledge about specific data subjects. Due to the critical importance of addressing privacy issues in many business domains, the employment of privacy-protection techniques that offer formal privacy guarantees has become a necessity. This has paved the way for the development of privacy models and techniques such as differential privacy, private information retrieval, syntactic anonymity, homomorphic encryption, secure search encryption and secure multiparty computation, among others. The maturity of these technologies varies, with some, such as k-anonymity, more established than others. However, none of these technologies has so far been applied to large-scale commercial data processing tasks involving big data.
In addition to the privacy guarantees that can be offered by state-of-the-art privacy-enhancing technologies, another important consideration concerns the ability of the data protection approaches to maintain the utility of the datasets to which they are applied, with the goal of supporting different types of data analysis. Privacy solutions that offer guarantees while maintaining high data utility will make privacy technology a key enabler for the application of analytics to proprietary and potentially sensitive data.
A truly modern and harmonised legal framework on data protection which has teeth and can be enforced appropriately will ensure that stakeholders pay attention to the importance of data protection. At the same time, it should enable the uptake of big data and incentivise privacy-enhancing technologies, which could be an asset for Europe as this is currently an underdeveloped market. In addition, users are beginning to pay more attention to how their data are processed. Hence, firms operating in the digital economy may realise that investing in privacy-enhancing technologies could give them a competitive advantage.
Data Management
This concern covers principles and techniques for data management, including data ingestion, sharing, integration, cleansing and storage. More and more data are becoming available. This data explosion, often called a “data tsunami”, has been triggered by the growing volumes of sensor data and social data, born out of Cyber-Physical Systems (CPS) and Internet of Things (IoT) applications. Traditional means for data storage and data management are no longer able to cope with the size and speed of data delivered in heterogeneous formats and at distributed locations.
Large amounts of data are being made available in a variety of formats – ranging from unstructured to semi-structured to structured – such as reports, Web 2.0 data, images, sensor data, mobile data, geospatial data and multimedia data. Important data types include numeric types, arrays and matrices, geospatial data, multimedia data and text. A great deal of this data is created or converted and further processed as text. Algorithms or machines are not able to process the data sources due to the lack of explicit semantics. In Europe, text-based data resources occur in many different languages, since customers and citizens create content in their local language. This multilingualism of data sources means that it is often impossible to align them using existing tools because they are generally available only in the English language. Thus, the seamless aligning of data sources for data analysis or business intelligence applications is hindered by the lack of language support and gaps in the availability of appropriate resources.
Isolated and fragmented data pools are found in almost all industrial sectors. Due to the prevalence of data silos, it is challenging to accomplish seamless integration with and smart access to the various heterogeneous data sources. And still today, data producers and consumers, even in the same sector, rely on different storage, communication and thus different access mechanisms for their data. Due to the lack of commonly agreed standards and frameworks, the migration and federation of data between pools impose high levels of additional costs. Without a semantic interoperability layer being imposed upon all these different systems, the seamless alignment of data sources cannot be realised.
In order to ensure a valuable big data analytics outcome, the incoming data has to be of high quality, or, at least, the quality of the data should be known to enable appropriate judgements to be made. This requires differentiating between noise and valuable data, and thereby being able to decide which data sources to include and which to exclude to achieve the desired results.
Over many years, several different application sectors have tried to develop vertical processes for data management, including specific data format standards and domain models. However, consistent data lifecycle management – that is, the ability to clearly define, interoperate, openly share, access, transform, link, syndicate and manage data – is still missing. In addition, data, information and content need to be syndicated from data providers to data consumers while maintaining provenance, control and source information, including IPR considerations (data provenance). Moreover, to ensure transparent and flexible data usage, the aggregation and management of respective datasets enhanced by a controlled access mechanism through APIs should be enabled (Data-as-a-Service).
Cloud and High-Performance Computing (HPC)
Efficient big data processing, data analytics and data management require the effective use of Cloud and High-Performance Computing infrastructures to address the computational resource and storage needs of big data systems.
Cloud
Data ecosystems, promoted by the BDVA, should include strong links to scientific research that is becoming predominantly data driven. The BDVA is in a strong position to nurture such links as it has established strong relationships with European big data academia. However, a lack of access, trust and reusability prevents European researchers in academia and industry from gaining the full benefits of data-driven science. Most datasets from publicly funded research are still inaccessible to the majority of scientists in the same discipline, not to mention other potential users of the data, such as company R&D departments. Approximately 80% of research data is not in a trusted repository. However, even if the data openly appears in repositories, this is not always enough. As a current example, only 18% of the data in open repositories is reusable.1 This leads to inefficiencies and delays; in recent surveys, the time reportedly spent by data scientists in collecting and cleaning data sources made up 80% of their work (G. Press 2016).
In response to these challenges, the Commission has launched a large effort to create “a European Open Science Cloud to make science more efficient and productive and let millions of researchers share and analyse research data in a trusted environment across technologies, disciplines and borders”1. The initial outline for the European Open Science Cloud (EOSC) was laid out in the report from the High-Level Expert Group.2 The report advised the Commission on several measures needed to implement the governance and the financial scheme of the European Open Science Cloud, such as being based on a federated system of existing and emerging research (e-)infrastructures operating under light international governance with well-defined Rules of Engagement for participation. Machine understanding of data – based on common or widely used data standards – is required to handle the exponential growth in publications. Attractive career paths for data experts should be created through proper training and by applying modern reward and recognition practices. This should help to satisfy the growing demand for data scientists working together with substance scientists. Turning science into innovation is emphasised, and alongside this there is a need for industry, especially SMEs and start-ups, to be able to access the appropriate data resources.
A first phase aims at establishing a governance and business model that sets the rules for the use of the EOSC, creating a cross-border and multi-disciplinary open innovation environment for research data, knowledge and services, and ultimately establishing global standards for the interoperability of scientific data.
The EU has already initiated and will go on to launch several more infrastructure projects, such as EOSC-hub, within H2020 for implementing and piloting the EOSC. In addition to these projects, Germany and the Netherlands, among other countries, are promoting the GO FAIR initiative (Germany and the Netherlands 2017). The FAIR principles aim to ensure that Data and Digital Research Objects are Findable, Accessible, Interoperable and Reusable (FAIR) (Wilkinson et al. 2016). As science becomes increasingly data driven, making data FAIR will create real added value since it allows for combining datasets across disciplines and across borders to address pressing societal challenges that are mostly interdisciplinary.
The GO FAIR initiative is a bottom-up, open-to-all, cross-border and cross-disciplinary approach aiming to contribute to a broad involvement of the European science community as a whole, including the “long tail” of science.
The EOSC initiative is aligned with the BDVA agenda, as both promote data accessibility, trustworthiness and reproducibility over domains and borders. In the BDVA, this mainly applies to the i-Spaces and Lighthouse instruments, where the interoperability of datasets is central. Data standardisation is a self-evident topic for cooperation, but there are also common concerns in non-technical priorities – most notably skills development (relating to data-intensive engineers and data scientists). Both industry and academia benefit from findable, accessible, interoperable and reproducible data.
High-Performance Computing
In some sectors, big data applications are expected to move towards more computation-intensive algorithms to reap deeper insights across descriptive (explaining what is happening), diagnostic (exploring why it happens), prognostic (predicting what can happen) and prescriptive (proactive handling) analysis. The adoption of specific HPC-type capabilities by the big data analytics stack is likely to be of assistance where big data insights will be of the utmost value. Faster decision-making is crucial and extremely complex datasets are involved – i.e. extreme data analytics.
The Big Data and HPC communities (through BDVA and ETP4HPC collaboration1) have recognised their shared interests in strengthening Europe’s position regarding extreme data analytics. Recent engagements between PPPs have focused on the relevant issues of looking at how HPC and Big Data platforms are implemented, understanding the platform requirements for HPC and Big Data workloads, and exploring how the cross-transfer of certain technical capabilities belonging to either HPC or big data could benefit each other. For example, the application of deep learning is one such workload that readily stands to benefit from certain HPC-type capabilities regarding optimising and parallelising difficult optimisation problems.
Major technical requirements include highly scalable performance, high memory bandwidth, low power consumption and excellent short arithmetic performance. Additionally, more flexible end-user education paths, utilisation and business models will be required to capitalise on the rapidly evolving technologies underpinning extreme data analytics, as well as continued support for collaboration across the communities of both big data and HPC to jointly define the way forward for Europe.
IoT, CPS, Edge and Fog Computing
The main source of big data is sensor data from an IoT context and actuator interaction in Cyber-Physical Systems. To meet real-time needs, it will often be necessary to handle big data aspects at the edge of the system. This area is separately elaborated further in collaboration with the IoT (Alliance for Internet of Things Innovation (AIOTI)) and CPS communities.
Internet of Things (IoT) technology, which enables the connection of any type of smart device or object, will have a profound impact on many sectors in the European economy. Fostering this future market growth requires the seamless integration of IoT technology (such as sensor integration, field data collection, Cloud, Edge and Fog computing) and big data technology (such as data management, analytics, deep analytics, edge analytics and processing architectures).
The mission of the Alliance of Internet of Things Innovation (AIOTI) is to foster the European IoT market uptake and position by developing ecosystems across vertical silos, contributing to the direction of H2020 large-scale pilots, gathering evidence on market obstacles for IoT deployment in the Digital Single Market context, championing the EU in spearheading IoT initiatives, and mapping and bridging global, EU and Members States’ IoT innovation and standardisation activities. AIOTI working groups cover various vertical markets from smart farming to smart manufacturing and smart cities, and specific horizontal topics on standardisation, policy, research and innovation ecosystems. The AIOTI was launched by the European Commission in 2015 as an informal group and established as a legal entity in 2016. It is a major cross-domain European IoT innovation activity.Close cooperation between the AIOTI and the BDVA is seen as being very beneficial for the BDVA. The following areas of collaboration are of particular interest to the BDVA:
- Alignment of high-level reference architectures: A common understanding of how the AIOTI High-Level Architecture (HLA) and the BDVA Reference Model are related to each other enables well-grounded decisions and prioritisations related to the future impact of technologies.
- Deepening the understanding about sectorial needs: Through the mutual exchange of roadmaps, accompanied by insights about sectorial needs in the various domains, the BDVA will receive additional input about drivers for and constraints on the adoption of big data in the various sectors. In particular, insights about sector-specific user requirements as well as topics related to the BDV strategic research and innovation roadmap will be fed back into our ongoing updating process.
- Standardisation activities: To foster the seamless integration of IoT and big data technologies, the standardisation activities of both communities should be aligned whenever technically required. In addition, the BDVA can benefit from the already established partnerships between the AIOTI and standardisation bodies to communicate big-data-related standardisation requirements.
Aligning Security Efforts
The efforts to strengthen security in the IoT domain will have a huge impact on the integrity of data in the big data domain. When IoT security is compromised, so too is the generated data. By developing a mutual understanding on security issues in both domains, trust in both technologies and their applications will be increased.
Vertical Concerns
Vertical concerns address cross-cutting issues, which are relevant and may affect more than one of the horizontal concerns. They may not be purely technical and also involve some non-technical aspects.
Big Data Types and Semantics
One specific vertical concern defined by the BDV Reference Model is data types. Different data types may require the use of different techniques and mechanisms in the horizontal concerns, for instance for data analytics and data storage.
The following six big data types have been identified as the main relevant data types used in big data systems: (1) structured data, (2) time series data, (3) geospatial data, (4) media data (image, video, audio, etc.), (5) text data (including natural language data and genomics representations) and (6) graph or network data. In addition, it is important to support both the syntactical and semantic aspects of data for all big data types, in particular, considering metadata.
Standards
This concern covers the standardisation of big data technology areas to facilitate data integration, sharing and interoperability.Standardisation is a fundamental pillar in the construction of a Digital Single Market and Data Economy. It is only through the use of standards that the requirements of interconnectivity and interoperability can be ensured in an ICT-centric economy. The PPP will continue to lead the way in the development of technology and data standards for big data by:
- Leveraging existing common standards as the basis for an open and successful big data market
- Supporting standards development organisations (SDOs), such as ETSI, CEN-CENELEC, ISO, IEC, W3C, ITU-T and IEEE, by making experts available for all aspects of big data in the standardisation process
- Aligning the BDV Reference Model with existing and evolving compatible architectures
- Liaising and collaborating with international consortia and SDOs through the TF6SG6 Standards Group and Workshops
- Integrating national efforts on an international (European) level as early as possible
- Providing education and educational material to promote developing standards
Standards are the essential building blocks for product and service development as they define clear protocols that can be easily understood and adopted internationally. They are a prime source of compatibility and interoperability and simplify product and service development as well as speeding the time-to-market. Standards are globally adopted; they make it easier to understand and compare competing products, and thus drive international trade.
In the data ecosystem, standardisation applies to both the technology and the data.
Technology Standardisation
Most technology standards for big data processing are de facto standards that are not prescribed (but are at best described after the fact) by a standards organisation. However, the lack of standards is a significant obstacle. One example is the NoSQL databases. The history of NoSQL is based on solving specific technology challenges that lead to a range of different storage technologies. The broad range of choices, coupled with the lack of standards for querying the data, makes it harder to exchange data stores, as this may tie application-specific code to a specific storage solution. The PPP is likely to take a pragmatic approach to standardisation and look to influence, in addition to NoSQL databases, the standardisation of technologies such as complex event processing for real-time big data applications, languages to encode the extracted knowledge bases, Artificial Intelligence, computation infrastructure, data curation infrastructure, query interfaces and data storage technologies.
Data Standardisation
The “variety” of big data makes it very difficult to standardise. Nevertheless, there is a great deal of potential for data standardisation in the areas of data exchange and data interoperability. The exchange and use of data assets are essential for functioning ecosystems and the data economy. Enabling the seamless flow of data between participants (i.e. companies, institutions and individuals) is a necessary cornerstone of the ecosystem.
To this end, the PPP is likely to undertake collaborative efforts to support, where possible and pragmatic, the definition of semantic standardised data representation, ranging from the domain (industry sector)-specific solutions, like domain ontologies, to general concepts, such as Linked Open Data, to simplify and reduce the costs of data exchange.
In line with JTC1 Directives Clause 3.3.4.2, the Big Data Value Association (BDVA) requested the establishment of a Category C liaison with the ISO/IEC JTC1/WG9 Big Data Reference Architecture. This request was processed at the August Plenary meeting of ISO IEC JTC1 WG9, and the recommendation was unanimously approved by the working group. This liaison moves the BDVA work forward from a technology standardisation viewpoint, and now the BDVA Big Data Reference Model is closely aligned with the ISO Big Data Reference Architecture, as described in ISO IEC JTC1 WG9 20547-3. The BDVA TF6SG6 Standardisation Group is now also in the process of using the WG9 Use Case Template to extract data from the PPP Projects to extend the European use case influence on the ISO big data standards.
As the data ecosystem overlaps with many other ecosystems, such as Cloud computing, IoT, smart cities and Artificial Intelligence, the PPP will continue to be a forum for bringing together industry stakeholders from across these other domains to collaborate. These fora will continue to drive interoperability within the big data domain but will also extend this activity across the other technological ecosystems.
Communication and Connectivity
This concern covers effective communication and connectivity mechanisms, which are necessary for providing support for big data. This area is separately further elaborated, along with various communication communities, such as the 5G community.
The 5G PPP will deliver solutions, architectures, technologies and standards for the ubiquitous next generation of communication infrastructures in the coming decade. It will provide 1000 times higher wireless area capacity by facilitating very dense deployments of wireless communication links to connect over 7 trillion wireless devices serving over 7 billion people. This guarantees access to a wider panel of services and applications for everyone, everywhere.
5G provides the opportunity to collect and process big data from the network in real time. The exploitation of Data Analytics and big data techniques supports Network Management and Automation. This will pave the way to monitoring users’ Quality of Experience (QoE) and Quality of Service (QoS) through new metrics combining network and behavioural data while guaranteeing privacy. 5G is also based on flexible network function orchestration, where machine learning techniques and approaches from big data handling will become necessary to optimise the network.
Turning to the IoT arena, the per-bit value of IoT is relatively low, while the value generated by holistic orchestration and big data analytics is enormous. Combinations of 5G infrastructure capabilities, big data assets and IoT development may help to create more value, increased sector knowledge and ultimately more ground for new sector applications and services.
On the agenda of 5G PPP is the realisation of prototypes, technology demos, and pilots of network management and operation, Cloud-based distributed computing, edge computing and big data for network operation – as is the extension of pilots and trials to non-ICT stakeholders to evaluate the technical solutions and their impact on the real economy.
The aims of 5G PPP are closely related to the agenda of the BDVA. Collaborative interactions involving both ecosystems (e.g. joint events, workshops and conferences) could provide opportunities for the BDVA and 5G PPP to advance understanding and definition in their respective areas. The 5G PPP and BDVA ecosystems need to increase their collaboration with each other, and in so doing could develop joint recommendations related to big data.
Cybersecurity
This concern covers security and trust elements that go beyond privacy and anonymisation. The aspect of trust frequently has links to trust mechanisms such as blockchain technologies, smart contracts and various forms of encryption.
Cybersecurity and big data naturally complement each other and are closely related, for instance in using cybersecurity algorithms to secure a data repository, or reciprocally, using big data technologies to build dynamic and smart responses and protection from attacks (web crawling to gather information and learning techniques to extract relevant information).
By its nature, any data manipulation presents a cybersecurity challenge. The issue of Data Sovereignty perfectly illustrates the way in which both technologies can be intertwined. Data Sovereignty consists in merging personal data from several sources, always allowing the data owner to retain control over their data, be it by partial anonymisation, secure protocols, smart contracts or other methods. The problem as a whole cannot be solved by considering each of these technologies separately, especially those relevant to cybersecurity and big data. The problem has to be solved globally, taking a functionally complete and secure-by-design approach.
In the case of personal data space, both security and privacy should be considered. For industrial dataspaces, the challenges relate more to the protection of IPRs, the protection of data at large and the secure processing of sensitive data in the Cloud.
In terms of research and innovation, several topics have to be considered, for example homomorphic encryption, threat intelligence and how to test a learning process, assurance in gaining trust, differential privacy techniques for privacy-aware big data analytics and the protection of data algorithms.
Artificial Intelligence could be used and could even be more efficient in attacking a system rather than protecting it. The impact of falsified data, and trust in data, should also be considered. It is essential to define the concepts of measurable trust and evidence-based trust. Data should be secured at rest and in motion.
The European Cyber Security Organisation (ECSO) represents the contractual counterpart to the European Commission for the implementation of the Cybersecurity contractual Public-Private Partnership (PPP)1. A collaboration with ECSO, supporting the Cybersecurity PPP, has been initiated and further steps planned.
Engineering and DevOps for Building Big Data Value Systems
This concern covers methodologies for developing and operating big data systems.
While big data technologies gain significant momentum in research and innovation, mature, proven and empirically sound engineering methodologies for building next-generation big data value systems are not yet available. Moreover, we lack proven approaches for continuous development and operations (DevOps) of big data value systems. The availability of engineering methodologies and DevOps approaches – combined with adequate toolchains and big data platforms – will be essential for fostering productivity and quality. As a result, these methodologies and approaches will empower the new wave of data professionals to deliver high-quality next-generation big data value systems.
Marketplaces, Industrial Data Platforms and Personal Data Platforms (IDPs/PDPs), Ecosystems for Data Sharing and Innovation Support
This concern covers data platforms for data sharing, which include, in particular, IDPs and PDPs, but also other data sharing platforms such as Research Data Platforms (RDPs), Data Platforms for Smart Environments (Curry 2020) and Urban/City Data Platforms (UDPs). These platforms facilitate the efficient usage of a number of the horizontal and vertical big data areas, most notably data management, data processing, data protection and cybersecurity.
Data sharing and trading are seen as essential ecosystem enablers in the data economy, although closed and personal data present particular challenges for the free flow of data (Curry and Ojo 2020). The following two conceptual solutions – Industrial Data Platforms (IDPs) and Personal Data Platforms (PDPs) – introduce new approaches to addressing this particular need to regulate closed proprietary and personal data.
Excerpt from: Curry E., Metzger A., Berre A.J., Monzón A., Boggio-Marzet A. (2021) A Reference Model for Big Data Technologies. In: Curry E., Metzger A., Zillner S., Pazzaglia JC., García Robles A. (eds) The Elements of Big Data Value. Springer, Cham. https://doi.org/10.1007/978-3-030-68176-0_6
References:
- Zillner, S, Curry, E., Metzger, A., & Auer, S. (Eds.). (2017). European big data value strategic research & innovation agenda. Retrieved from Big Data Value Association website www.bdva.eu
- Raskin, J. (2000). Humane interface, the: New directions for designing interactive systems. Addison-Wesley Professional.
- Cavanillas, J. M., Curry, E., & Wahlster, W. (Eds.). (2016). New horizons for a data-driven economy: A roadmap for usage and exploitation of big data in Europe. https://doi.org/10.1007/978-3-319-21569-3
- Manyika, J., Chui, M., Brown, B., Bughin, J., Dobbs, R., Roxburgh, C., & Byers, A. H. (2011). Big data: The next frontier for innovation, competition, and productivity. Retrieved from McKinsey Global Institute website https://www.mckinsey.com/business-functions/mckinsey-digital/our-insights/big-data-the-next-frontier-for-innovation
- Lund, S., Manyika, J., Nyquist, S., Mendonca, L., & Ramaswamy, S. (2013). Game changers: Five opportunities for US growth and renewal.
- G. Press. (2016). Cleaning big data: Most time-consuming, least enjoyable data science task, survey says.
- Germany and the Netherlands. (2017). Joint position paper on the European open science cloud.
- Wilkinson, M. D., Dumontier, M., Aalbersberg, IJ., Appleton, G., Axton, M., Baak, A., et al. (2016). The FAIR guiding principles for scientific data management and stewardship. Scientific Data, 3, 160018. https://doi.org/10.1038/sdata.2016.18
- Curry, E. (2020). Real-time linked dataspaces.
- Curry, E., & Ojo, A. (2020). Enabling knowledge flows in an intelligent systems data ecosystem. In Real-time Linked Dataspaces (pp. 15–43). https://doi.org/10.1007/978-3-030-29665-0_2